Agentic coding with Claude Code: what changes after the demo
The phrase agentic coding is easy to dislike. It sounds like another label invented five minutes before a product launch.
I still think the label is useful, but only if we stop using it as a shiny synonym for “AI wrote some code”.
Here is my bias: agentic coding is not a prompt trick. It is not a benchmark category. It is a production discipline.
A normal coding assistant suggests code. An agentic coding system can inspect a repository, edit files, run tests, use tools, recover from errors, and hand back a change that looks close to something a human developer would have done. Claude Code is the clearest version of this pattern right now because it lives close to the codebase and actually takes action.
That is exactly why it should make engineering leaders more demanding, not less.
The old question was, “can AI generate code?” That question is now too small. The better question is: can the team trust the path from instruction to change?
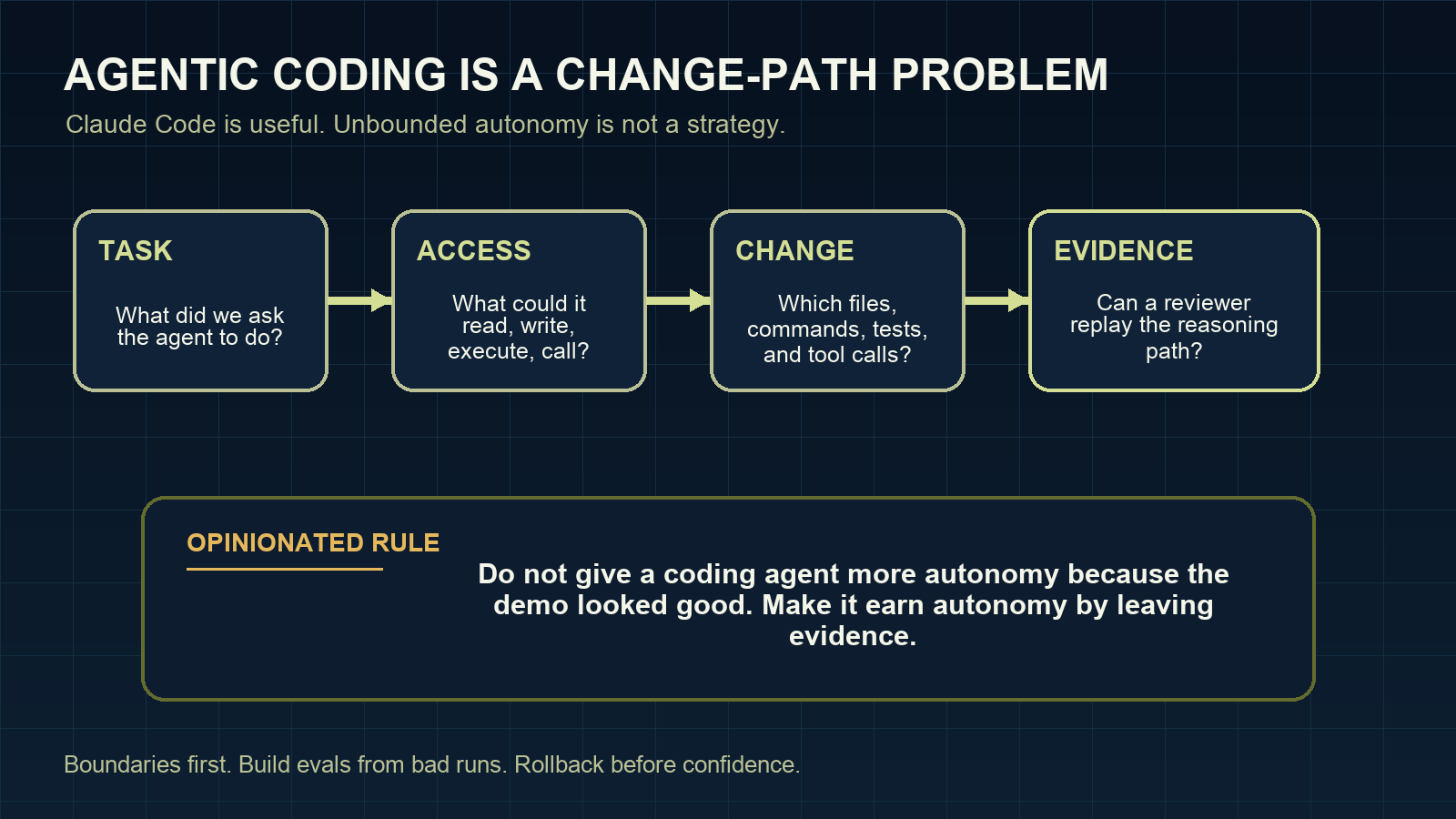
The demo version is not the production version
The demo version of agentic coding is seductive. Give Claude Code a task. Watch it read the project. Watch it edit three files, run tests, fix the first mistake, and explain the result.
That moment is useful. I still enjoy it.
But I do not trust a demo. I trust a trail.
But a production codebase changes the meaning of the same behavior. A tool that can edit a file can edit the wrong file. A tool that can run a command can run it in the wrong directory. A tool that can call an API can call the wrong system. A tool that can “fix” a failing test can weaken the assertion instead of fixing the bug.
None of that requires the model to be malicious. Competence is enough to create risk when the operating boundaries are vague.
This is where many discussions about agentic coding get stuck. They focus on the model, the prompt, or the benchmark. Those matter, but they are not the whole system. In serious software development, the system includes the repo, tools, permissions, tests, reviewers, deployment path, incident process, and audit trail.
Claude Code is part of that system. It is not the whole thing.
The real unit of work is the change path
When an AI coding agent opens a change, I want to know more than whether the final diff looks plausible.
I want to know:
- what task it was given
- which files it read before editing
- which files it changed
- which commands it ran
- which tests passed, failed, or were skipped
- which permissions it had at the time
- where a human approved or rejected risk
- how the change can be rolled back
That is the change path. It is the difference between “the agent wrote code” and “the team can reason about what happened”.
This is also where Claude Code can be much more useful than generic AI code generation. Because it works inside the development workflow, it can produce evidence around the work if the team asks for it and designs for it.
The mistake is to treat that evidence as optional. If the agent cannot show its work in a way a reviewer can inspect, it has not finished the job. It has only produced a diff.
Agentic coding needs boundaries before autonomy
A good agentic coding workflow starts with constraints, not freedom.
That sounds conservative. It is not. It is how you get to useful autonomy without pretending every repo is a toy repo.
The first version should be almost boring:
- a known working directory
- a small task scope
- blocked secret paths
- limited shell commands
- no broad network access by default
- explicit review before risky edits
- acceptance checks that must be shown, not merely claimed
Only after the workflow behaves well under those limits should the team widen autonomy.
That order matters. If you start with broad access because the demo looked impressive, you are borrowing speed from the future. The payback usually arrives as review fatigue, surprise diffs, messy rollback, or a quiet security exception nobody wanted to own.
Evals should come from bad runs
A lot of teams ask for an eval strategy before they have collected the failures that matter.
I would start with the run that made someone uncomfortable.
The agent edited a generated file. It touched a migration without being asked. It changed a test expectation to make the suite pass. It skipped the expensive integration test and wrote a cheerful summary anyway. That kind of run is not just an anecdote. It is raw material.
Turn it into a small replayable case:
- the original task
- the starting repo state
- the files the agent may touch
- the files it must not touch
- the commands it should run
- the behavior that counts as failure
Now the eval is tied to your actual risk, not an abstract leaderboard.
This is one of the strongest arguments for treating agentic coding as production engineering rather than prompt craft. The control loop matters. Bad runs feed evals. Evals shape permissions. Permissions shape how much autonomy the workflow earns.
Claude Code makes the operating model visible
The reason I keep writing about Claude Code is not that it magically removes software engineering judgment. It does the opposite. It exposes where judgment was missing.
If a team has unclear ownership, weak tests, vague review habits, and no rollback discipline, a coding agent will not fix that. It may make the weakness visible faster.
If a team has strong boundaries, useful tests, good review culture, and a habit of leaving evidence behind, Claude Code can become a serious accelerator.
That is the real split I see forming. Not teams that use AI versus teams that do not. Teams with an operating model versus teams running a powerful tool on vibes.
A practical starting point
Before treating Claude Code or any AI coding agent as part of a production workflow, I would put this in place:
- Define the workspace boundary.
- Block secrets and sensitive paths explicitly.
- Separate read, write, shell, network, and MCP permissions.
- Require evidence for tests and checks.
- Capture a flight recorder for prompts, tool calls, diffs, approvals, and rollback notes.
- Build evals from bad runs before expanding autonomy.
- Keep human review for actions where judgment changes the outcome.
That is less glamorous than a viral demo. It is also what lets a team keep using the tool after the first uncomfortable surprise.
My opinion is simple: if an agentic coding workflow cannot explain what it touched, what it ran, what it skipped, and how to undo it, it is not production-ready. It is a clever local experiment.
I am writing the longer version of this in Claude Code: Building Production Agents That Actually Scale. If you want the short operational version first, start with the Claude Code production readiness checklist.
Related reading: Claude Code agents need a flight recorder, Claude Code permissions: the production mistake that bites later, Claude Code evals should start with bad runs, Claude Code rollback plans belong in the prompt, and the Claude Code review packet I want before approving agent work.